 Collaborative semantic occupancy prediction leverages the power of collaborative perception and learning for 3D occupancy prediction and semantic segmentation. This approach enables a deeper understanding of the 3D road environment by sharing features among connected automated vehicles (CAVs), surpassing the ground truth (GT) captured by a multi-camera system in ego vehicle.
Collaborative semantic occupancy prediction leverages the power of collaborative perception and learning for 3D occupancy prediction and semantic segmentation. This approach enables a deeper understanding of the 3D road environment by sharing features among connected automated vehicles (CAVs), surpassing the ground truth (GT) captured by a multi-camera system in ego vehicle.
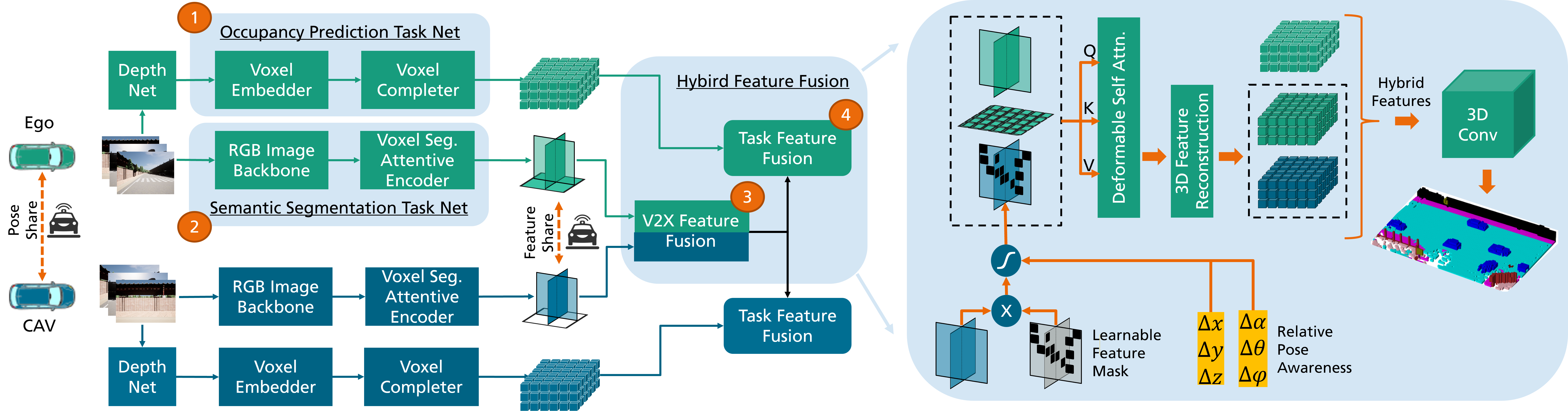 The CoHFF Framework consists of four key modules: (1) Occupancy Prediction Task Net, for occupancy feature extraction;
(2) Semantic Segmentation Task Net, creating semantic plane-based embeddings; (3) V2X Feature Fusion, merging CAV features via
deformable self-attention; and (4) Task Feature Fusion, uniting all task features to enhance semantic occupancy prediction.
The CoHFF Framework consists of four key modules: (1) Occupancy Prediction Task Net, for occupancy feature extraction;
(2) Semantic Segmentation Task Net, creating semantic plane-based embeddings; (3) V2X Feature Fusion, merging CAV features via
deformable self-attention; and (4) Task Feature Fusion, uniting all task features to enhance semantic occupancy prediction.
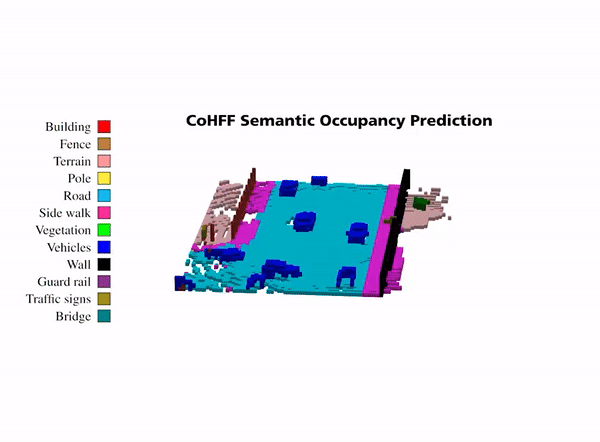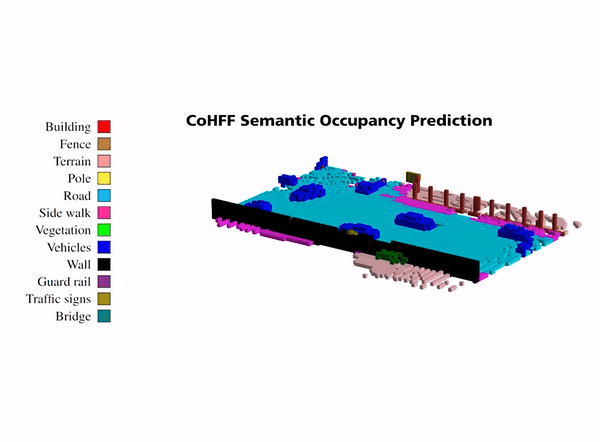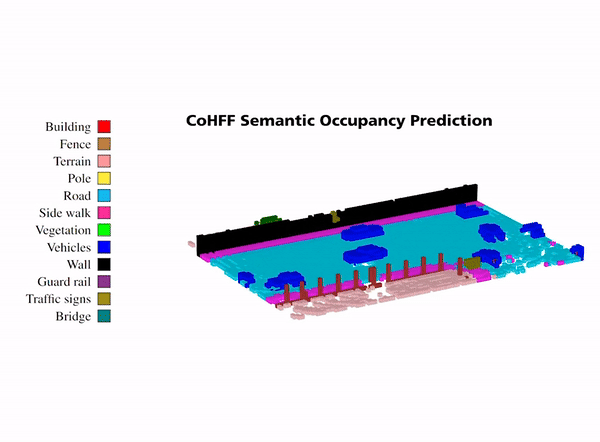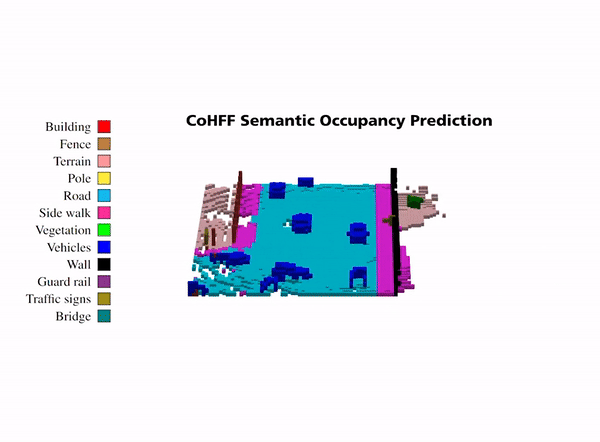

 Illustration of collaborative semantic occupancy prediction from multiple perspectives, compared to the ground truth in the
ego vehicle’s FoV and the collaborative FoV across CAVs. This visualization emphasizes the advanced object detection capabilities in
collaborative settings, particularly for objects obscured in the ego vehicle’s FoV, such as the vehicle with ID 6.
Illustration of collaborative semantic occupancy prediction from multiple perspectives, compared to the ground truth in the
ego vehicle’s FoV and the collaborative FoV across CAVs. This visualization emphasizes the advanced object detection capabilities in
collaborative settings, particularly for objects obscured in the ego vehicle’s FoV, such as the vehicle with ID 6.